
Do Not Read: Raf Is a Useless and Valueless Failed Experiment
本文链接: https://blog.openacid.com/algo/raf-without-term/

Summary:
raf: Raft without [T]ermis an experimental Raft variant. It does not persistcurrentTermas a separate piece of state. Instead, a candidate reserves a log index when it starts an election, and that index becomes the leader term. This does not remove Raft’s logical time model. It only changes where the term is derived from in storage.
Declaration: This approach is just the same as saving terms in the separate first extra slot in the terms array. So it actually still stores the term and has no value at all. Please do not read this as a useful design; it is only a failed personal experiment.
Note: The idea in this article came from Zhang Yanpo. The code was implemented by Zhang Yanpo by hand. This article was drafted and refined with Codex.
Repository: raf (v0.1.1).
Introduction
I have seen a few interesting proposals that try to remove the term from Raft. The idea is appealing: if a consensus protocol can maintain one less piece of persistent state, perhaps both the model and the implementation become simpler. But Raft’s term is not just a counter. It represents logical time, lets nodes distinguish old leaders from new ones, and participates in Raft’s commit safety rule. So the real question is not whether we can simply delete the term. The useful question is whether we can express it in a different way.
The name raf comes from Raft without [T]erm. Here, “without term” does not mean the protocol has no term at all. It means currentTerm is no longer persisted as an independent field. The project turns this idea into a small but serious implementation: avoid storing currentTerm separately, while still giving every part of Raft that needs a term a reliable source of logical time.
This article explains that core idea. The term still exists as a concept. Logs are still compared by (term, index). What changes is the source of the term: it no longer comes from a separately incremented persistent counter; it comes from a log index reserved by an election. The goal of this implementation is not to prove that it is a drop-in replacement for standard Raft in every engineering detail. The goal is to see whether this storage representation preserves the most important safety intuition behind Raft.
We will walk through the storage model, election, replication, commit, and the three-node example in the repository. I assume the reader is already familiar with the basic Raft flow: leader election, AppendEntries, quorum commit, and log ids in the form (term, index).
Why Term Cannot Disappear
In a consensus algorithm, the log records events that have been chosen or are being proposed. The term tells us which logical time those events belong to.
Standard Raft uses the term for several jobs:
- Leader election advances the term before choosing a leader. The term gives leaders an ordering.
- Because of that, log freshness is compared by term first, then by index.
- A leader may directly commit only entries from its own term.
This role is similar to the ballot number in Paxos. It lets the system decide which history is newer and which candidate is eligible to become leader, even when a node does not know every other node’s complete log.
In short: a log index is a local event position; a term is the logical time used to compare histories across nodes.
raf keeps the concept of term, but removes its separate storage.
Core Idea
Standard Raft usually persists state shaped roughly like this:
struct StandardRaftStorage {
current_term: Term,
voted_for: Option<NodeId>,
log: Vec<LogEntry>,
}
struct LogEntry {
term: Term,
cmd: Cmd,
}
raf represents the persistent state as two Vecs aligned by log index:
struct RafStorage {
terms: Vec<Term>,
cmds: Vec<Cmd>,
}
Here:
terms[i]is the leader term of the log entry at indexi.cmds[i]is the application command of the log entry at indexi.log_id(i)is still(terms[i], i).
The following is one possible storage state. ø means empty command. cmds only reaches index 7, so indexes 8 and 9 are not complete log entries yet.
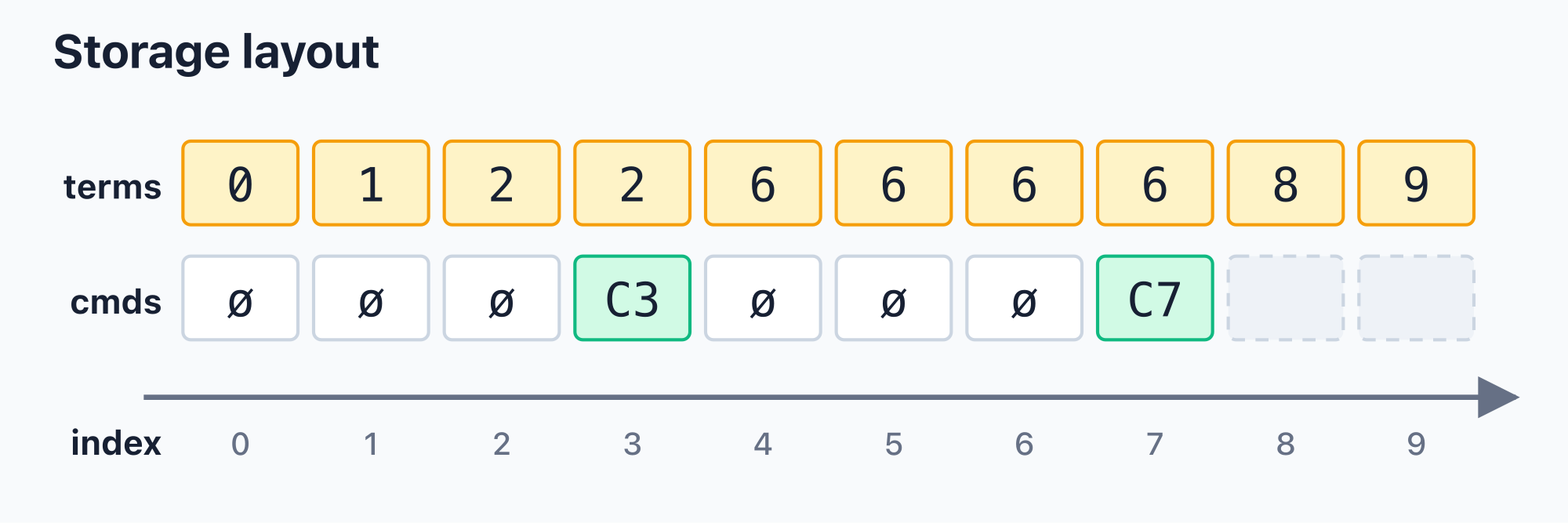
Index by index, this state means:
- Index
0: the fixed default entry.terms[0] = 0, andcmds[0]is an empty command. - Index
1: a successful election for term1. The leader reserved index1when it was elected and wrote its first empty command there. - Index
2: a successful election for term2. The new leader reserved index2; its first log entry is also an empty command. - Index
3: a user log entryC3written by the leader of term2, soterms[3] = 2andcmds[3] = C3. - Index
4: this position used to be an election attempt for term4, but it did not produce an established leader. Later, when the leader of term6was established, this position was filled as an empty command owned by term6, so nowterms[4] = 6. - Index
5: this position used to be another failed election attempt for term5. It was also later filled as an empty command owned by term6, so nowterms[5] = 6. - Index
6: a successful election for term6. The leader reserved index6when it was elected, and wrote its first empty command there. - Index
7: a user log entryC7written by the leader of term6, soterms[7] = 6andcmds[7] = C7. - Index
8: a new election attempt for term8. So far we have only seenterms[8] = 8; there is no command for this index yet, so it is not a complete log entry. - Index
9: another election attempt for term9. Like index8, it currently has only a term record and no command. From this state alone, we cannot tell whether it will eventually become a leader.
Standard Raft persists a separate current_term and an array of (term, command) log entries. raf is similar, but splits the term and command at each index into two aligned Vecs.
Storage Model
Index 0 is a fixed default entry. This keeps the types simple and avoids using Option for the initial position:
terms[0] = 0
cmds[0] = empty
When both Vecs have a value at the same index, that index is a complete log entry. Otherwise, the index has a term but no command. That state represents an election in progress: the term has been observed, but no log entry has been written at that position yet.
log[index] = (terms[index], cmds[index])
log_id = (terms[index], index)
terms and cmds share the same log index. During election, terms may be ahead of cmds.
During an election, terms can temporarily be longer than cmds. A candidate first reserves an index as its term. Multiple failed elections may reserve multiple indexes. Only after some candidate becomes an established leader are the positions with missing commands filled with empty commands.
So this implementation maintains a few basic facts:
cmdsshould never be longer thanterms.- When an election first reserves a term slot,
terms[term] = term. - When an established leader fills positions that still miss commands, those positions are rewritten to the current
leader.term.
Therefore terms[i] <= i is not a protocol invariant. A backfilled empty entry may have terms[i] > i. That is not a problem by itself; standard Raft terms can also be greater than log indexes. The important property is different: every complete log entry must carry the term of an established leader, except for the fixed default entry at index 0.
Why Split
terms
and
cmds
This implementation separates leader terms and application commands into two Vecs. Raft’s protocol semantics do not require this layout. It is mainly a storage design choice that creates room for cleaner optimization.
For example, a leader may write many consecutive log entries during one term, and all of those entries have the same term. A storage engine could compress long runs of identical terms into a compact representation, while storing commands according to application needs. Once the two streams are separated, term compression, command persistence, and payload encoding can evolve independently.
This is the experimental value of the project. It expresses the relationship between “logical time” and “log position” in Raft more directly, then asks whether that expression can simplify persistent state.
Starting an Election
When a candidate starts an election, it uses the next index of the terms array as the new term:
let term = terms.len();
terms.push(term);
In this code:
- The candidate declares that it wants to use
termas its leader term. - The local persistent state records that this index has been reserved by an election.
The candidate then sends RequestVote. This part is the same as standard Raft. The request carries two important pieces of information:
term: the leader term the candidate wants to use.last_log_id: the(term, index)of the candidate’s last complete log entry.
last_log_id is computed from the last index in cmds:
let last_log_index = cmds.len() - 1;
let last_log_id = (terms[last_log_index], last_log_index);
The meaning of last_log_id is the same as in standard Raft: the voter uses it to check whether the candidate’s log is at least as up to date as its own. Notice the separation here. The new election term comes from terms.len(), while last_log_id comes from cmds.len() - 1. These can point to different indexes.
In the following example, the complete log currently reaches only index 3, so last_log_id = (2, 3). When the candidate starts a new election, it uses terms.len() = 4 as the new term and first writes index 4 into terms. At this point, cmds still reaches only index 3, because this candidate has not become an established leader yet.
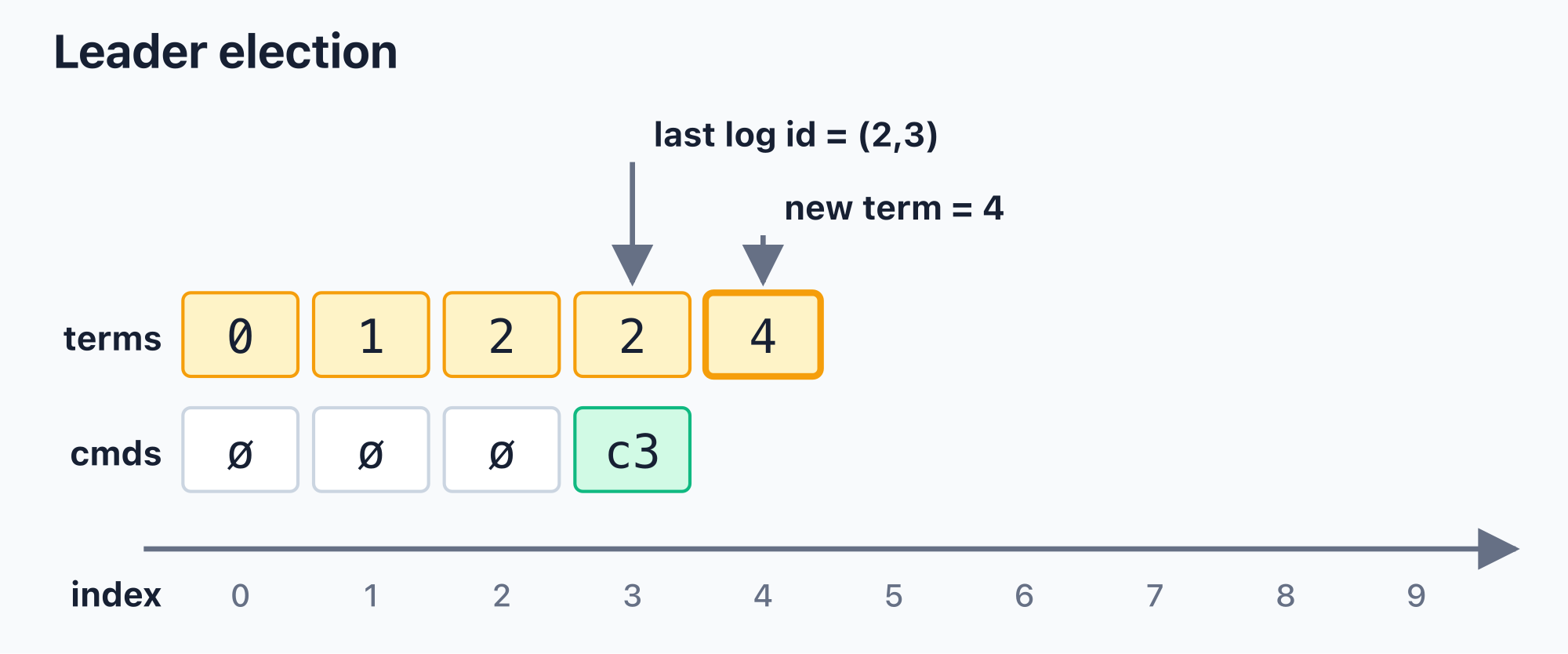
If the election for term 4 does not reach a quorum, it leaves only an observed term index in terms; it does not create a new command. The next election will use terms.len() again, which is now term 5.
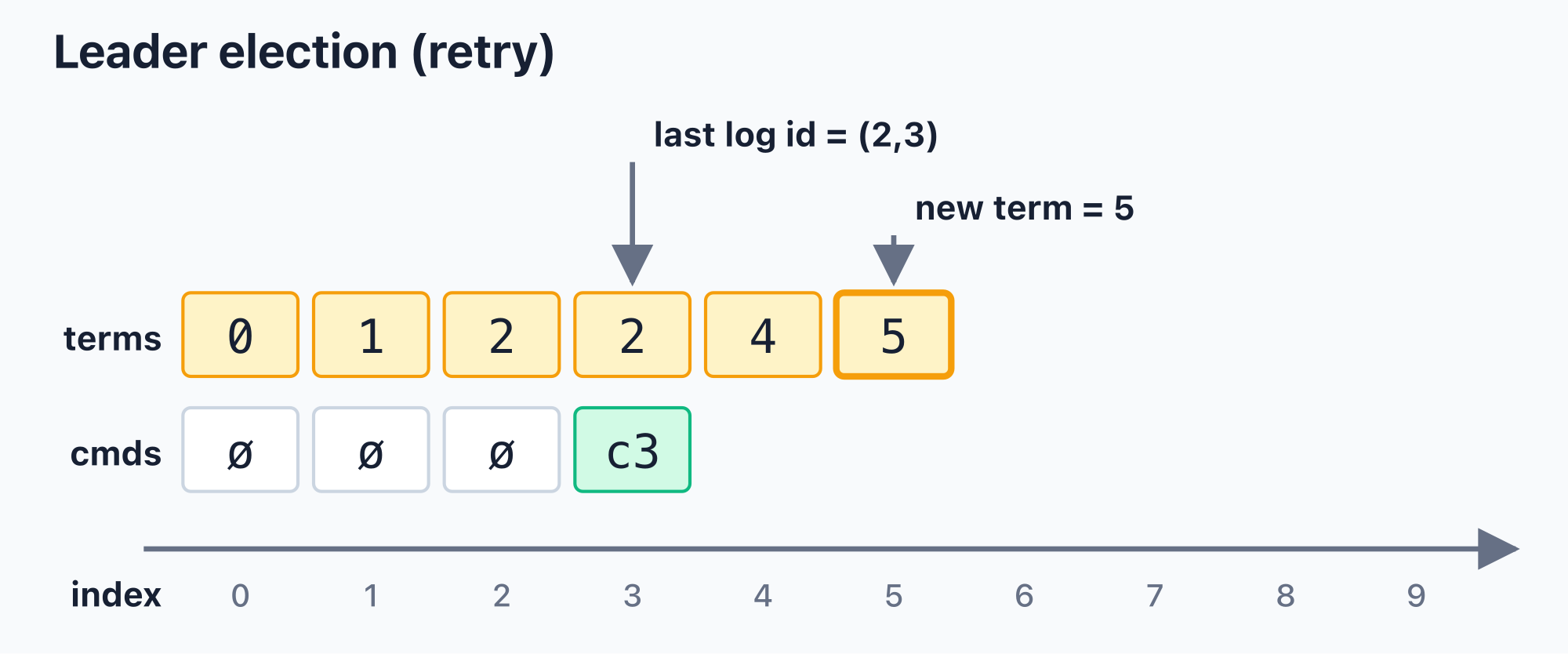
At this point last_log_id is still (2, 3), because cmds has not moved beyond index 3. What changed is the candidate term: it advanced from 4 to 5. Only after an election succeeds and a leader is established does the system rewrite the positions with missing commands to this leader’s term and fill cmds with empty commands.
How a Voter Handles RequestVote
When a voter receives RequestVote, it checks three things:
- Whether the requested term is greater than the last term observed locally.
- Whether the requested term slot does not already exist locally.
- Whether the candidate’s log, represented by
last_log_id, is fresh enough. It must not be older than the voter’s own log.
Aside from the term check, the rest of the logic is standard Raft. The subtle difference is that the term is no longer stored independently, so term freshness is expressed through terms.
The core condition looks like this:
let local_last_log_index = cmds.len() - 1;
let local_last_log_id = (terms[local_last_log_index], local_last_log_index);
let local_last_term = terms[terms.len() - 1];
let can_vote =
req.term > local_last_term
&& req.term >= terms.len()
&& req.last_log_id >= local_last_log_id;
The next diagram sends the same RequestVote { term: 5, last_log_id: (2, 3) } to voters with three different local states. The candidate’s own state is at the top. The three branches below it show how each voter makes its decision.
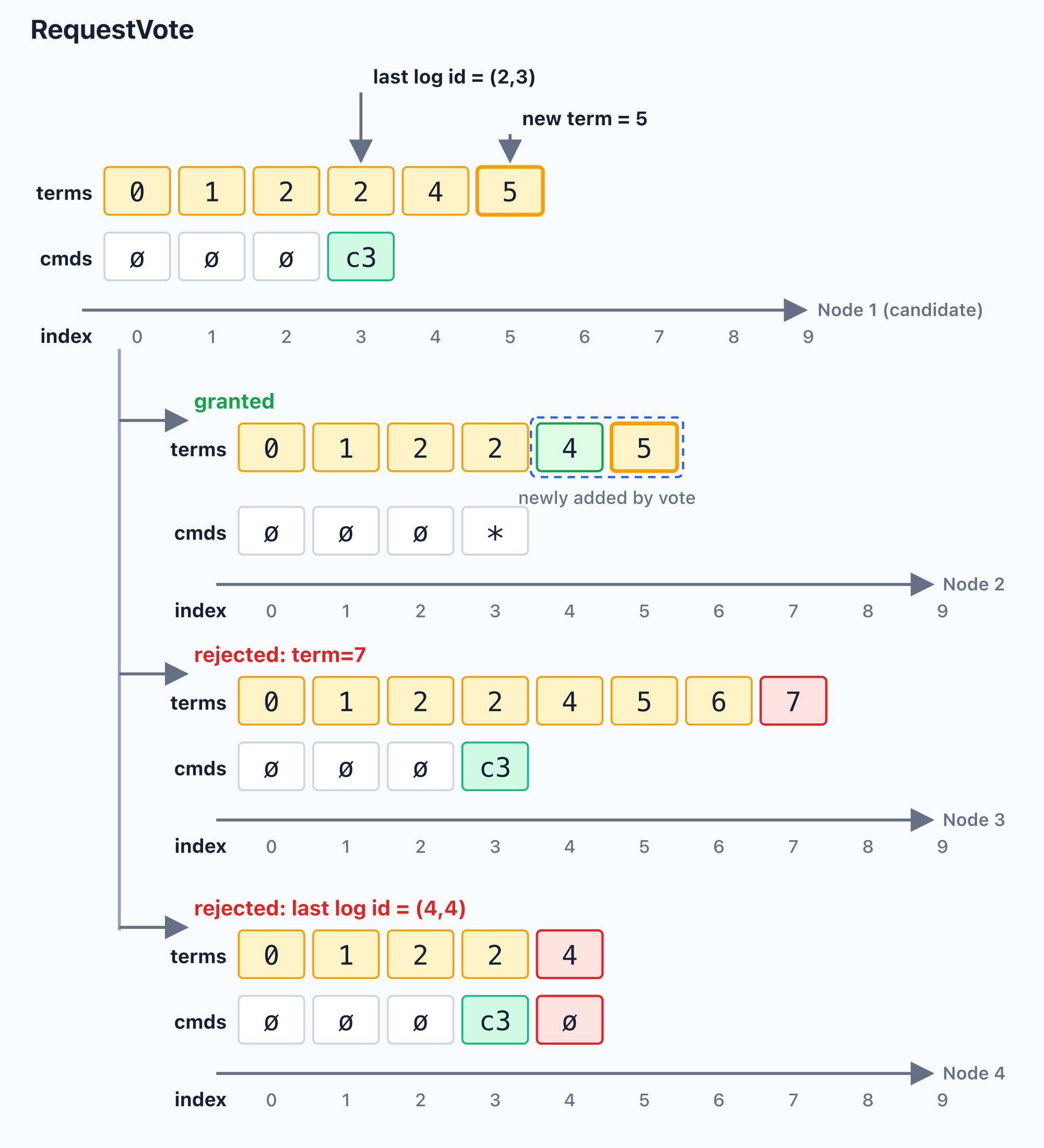
The three outcomes are:
granted: the voter’stermsreaches only index3, andcmdsalso reaches only index3. Thereforereq.term = 5is greater than the last locally observed term, names a term slot that has not appeared locally, andreq.last_log_id = (2, 3)is not behind the voter. The vote can be granted.rejected: term=7: the voter has already observed a later term7. Sincereq.term = 5is not greater than the last locally observed term, the candidate’s requested term is stale from this voter’s perspective, so the vote is rejected.rejected: last log id = (4,4): the voter’s last complete log entry is(4, 4), which is newer than the candidate’s(2, 3). Even if the requested term could be recorded, the log freshness check still fails, so the vote is rejected.
If the request is valid, the voter records the term in local terms. If local terms is shorter than req.term, it fills the missing positions with default indexes until local state contains index req.term:
if can_vote {
while terms.len() <= req.term {
let index = terms.len();
terms.push(index);
}
}
These default items have term values equal to their own indexes. They mean the node has observed the corresponding term indexes. They do not mean those indexes are complete log entries, because the matching cmds may not exist yet. If a later leader fills those positions as complete empty entries, it rewrites their terms to its own leader.term. On the final iteration, index == req.term, so the voter has observed and accepted that term. Later, it will not accept an older term or a term index that already exists locally.
This replaces the role of standard Raft’s persisted currentTerm, but it is not fully equivalent to standard Raft’s votedFor. The current implementation does not persist “which candidate this term was granted to.” As a result, RequestVote retry and restart behavior are more conservative. We will return to this trade-off in “Current Boundaries.”
The candidate chooses terms.len() as its term. Other nodes record that term in their local terms when they grant the vote.
After the candidate receives granted replies from a quorum, it becomes an established leader. It first rewrites the local cmds.len()..terms.len() range to its own leader.term, then appends empty commands so that cmds.len() catches up with terms.len(). The index reserved by the leader’s election becomes this leader’s first complete log entry.
Establishing Leader State
After a candidate becomes an established leader, it keeps the core state of this leadership in memory. You can think of it as the following structure:
struct LeaderState {
term: Term,
granted_nodes: Vec<NodeId>,
replications: BTreeMap<NodeId, ReplicationState>,
}
struct ReplicationState {
matched: LogIndex,
end: LogIndex,
inflight: bool,
}
The important fields are:
term: the log index reserved when this leader was elected. All later log entries produced by this leader write this term into the corresponding positions of thetermsarray.granted_nodes: the node ids that granted this leadership. This proves the leader was chosen by a quorum.replications: the replication progress of each node from the leader’s point of view.matchedis the largest index known to match on that node;endis the upper bound used for further probing or replication;inflightprevents sending multiple Append requests to the same node at the same time.
The leader also has its own replication state. This makes commit calculation uniform: look at which nodes have
matchedcovering an index, then check whether those nodes form a quorum.
After the leader is established, every position that already exists in local terms but is still missing from cmds is taken over by the current leader: the term at that position is rewritten to leader.term, and the command is filled with an empty command. After that, every local index on the leader has a corresponding command, and new application writes can start at the next index.
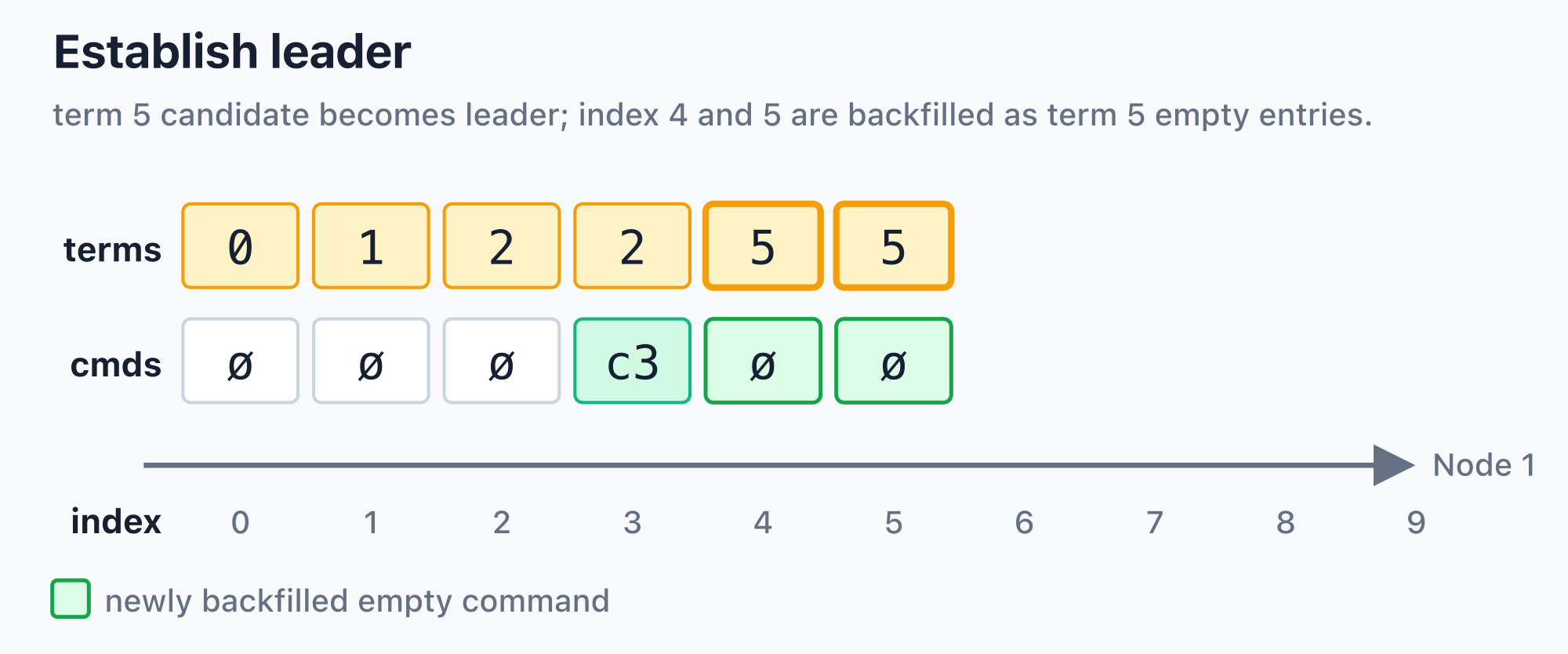
In this example, index 4 used to be a term slot left behind by a failed election, and term 5 is the index reserved by the current leader. When the candidate for term 5 becomes an established leader, indexes 4 and 5 are both rewritten as term 5 empty log entries. The ø at index 5 is the entry reserved by this leader’s election; the ø at index 4 is the backfilled entry that keeps the log prefix contiguous.
Appending a Log Entry
After a node becomes leader, each new application write appends a log entry. The term does not change. It is still the term chosen when the leader was elected:
terms.push(leader.term);
cmds.push(user_cmd);
So within one leader term, all later log entries have the same terms[i]. This matches standard Raft behavior. Only the source of the term is different.
Log Replication
The leader sends Append requests to the other nodes. Conceptually, each request first names a previous log id that is already known to match, then carries a contiguous segment of log entries after that position:
struct Append {
term: Term,
prev_log_id: LogId,
terms: Vec<Term>,
cmds: Vec<Cmd>,
}
Here prev_log_id is the matching point. terms and cmds are the real entries after that point. They must have the same length, and their first item corresponds to prev_log_id.index + 1. The follower first checks whether its local log has the same LogId at prev_log_id.index. Only if that previous position matches does it accept the entries that follow.
This design is close to standard Raft’s AppendEntries. Standard Raft carries prevLogIndex and prevLogTerm separately; raf combines them into a single prev_log_id. That is clearer than using the first entry in the request as the matching point, because the request’s terms and cmds represent only the real entries to replicate.
The following diagram shows one Append request applied to several follower states. The request has term = 5, prev_log_id = (2, 3), and carries the consecutive log entries for indexes 4..=5.
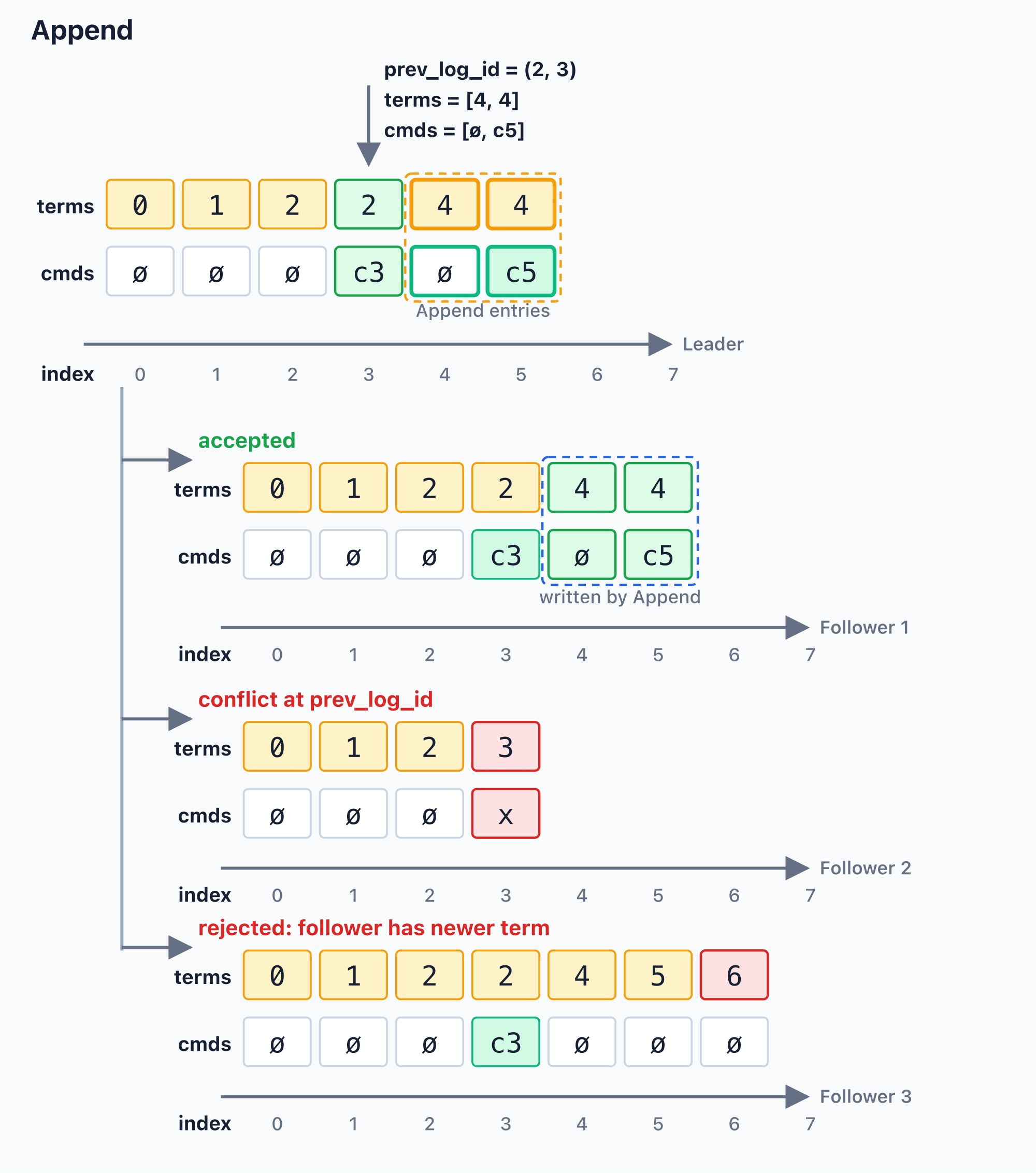
The three outcomes are:
accepted: the follower matches the leader atprev_log_id = (2, 3), so it can accept this Append.{...}marks thetermsrange overwritten by this request, as well as the command range appended because it was missing locally. Here the term at index4is updated from an old value to5, and commandc5is appended at index5.conflict at prev_log_id:*marks the conflict position. The follower’s term at index3is3, while the request’sprev_log_idis(2, 3). Since the previous log id does not match, the follower returns a conflict index immediately. The leader must try again with an earlierprev_log_id.rejected: follower has newer term: the follower has already observed term6at index6, while the Append request is from term5. This request comes from a stale leader, so the follower rejects it without modifying the log.
The handling logic is:
- If the request term is older than the last observed local term, reject it.
- Check the follower’s local log at
prev_log_id. If it does not match, return the conflict index. - If
prev_log_idmatches, process the real entries starting atprev_log_id.index + 1. - If later local commands diverge from the leader, truncate the local commands.
- Overwrite the local
termsrange covered by this request. - Append only the commands that are missing locally.
Append first finds the common prefix with prev_log_id, then truncates the follower’s conflicting suffix, and finally copies the leader’s entries that the follower is missing.
This is still Raft’s core replication model: the leader finds a shared log prefix, then replaces the follower’s divergent suffix with its own.
Advancing Commit
Replication to a quorum does not mean every historical entry can be committed immediately. Standard Raft has an important rule: a leader may only directly commit log entries from its own current term. Entries from older terms become committed only as a consequence of committing an entry from the current term.
raf keeps this rule. Although an established leader rewrites earlier gap slots to its own term, the leader still only directly commits matched indexes that are not smaller than its election index. Empty entries backfilled before leader.term are committed only indirectly, together with the leader’s election index or a later entry.
Intuitively:
if quorum_has_matched(index) && index >= leader.term {
commit(index);
}
The reason is the same as in standard Raft: once an index is committed, every future valid leader must contain it and must not overwrite it.
The following state shows why “replicated to a quorum” is not enough. The leader of term 6 has replicated the old log entries at indexes 4 and 5 to quorum A+B, but that quorum has not yet matched the leader’s own term index 6. Therefore indexes 4 and 5 still cannot be committed:

If a new leader for term 7 appears later, and its last_log_id=(5,6) is newer, it can overwrite those uncommitted log entries. In the diagram, {x} marks the range replaced by the new leader.
A leader only directly commits an index that is both covered by a quorum and inside the current leader’s term range.
Example
The repository includes a three-node in-process example that demonstrates the basic flow described in this article. It creates three Raf nodes, connects them with InProcessNetwork, explicitly triggers an election on node 1, and then writes a few log entries through the leader. Metrics show the role, term, commit index, and replication progress.
The example source is here:
https://github.com/drmingdrmer/raf/blob/v0.1.1/examples/three_node.rs
Run it from the repository root:
cargo run --example three_node
This example is not a production deployment template. It is a minimal demonstration for observing the core protocol state transitions. It logs to stderr and does not include an election timer, heartbeat, snapshots, or membership changes.
Current Boundaries
The current implementation is intentionally small. It leaves out several features that a complete production system would usually need:
- Automatic election triggering.
- Snapshots and log compaction.
- Membership changes.
- Heartbeats.
- RequestVote retry logic.
- Persistence semantics for application payloads.
Automatic election triggering corresponds to the election timer in standard Raft. A node periodically checks whether it has gone too long without seeing a valid leader. If it times out, it starts a new election. This can be implemented by an external timer that calls Raf::elect(). It does not need to live inside the core raf state machine, so the current implementation leaves it out.
RequestVote retry has a subtler boundary. Suppose a target node successfully handles a RequestVote, but the reply is lost in the network. If the candidate retries the same request, the target node has already recorded this term in terms[req.term]. Under the current rule, it rejects the retry because that term index already exists.
One optional fix is to add an in-memory voted_for field that records which candidate owns a term. Then a retry from the same candidate for the same term can be recognized and granted again. This field does not necessarily need to be persisted. If a node restarts and loses voted_for, it can conservatively reject every RequestVote that uses a term already present locally. That creates a small availability issue, but only after restart; it does not change the persisted relationship between logs and terms.
If a RequestVote reply is lost, the retry sees an already existing term. An optional in-memory voted_for field can improve availability in that case.
These features can all be added around the core model. This article focuses on the central question: if the term comes from the log index, can Raft election, replication, and commit still be expressed in the familiar way?
Summary
raf is not “Raft without any term.” It still has terms, and it still compares logs by (term, index). What it removes is the independently persisted currentTerm; the leader term is bound to the log index reserved by an election.
This change turns the storage state into two Vecs aligned by index:
struct RafStorage {
terms: Vec<Term>,
cmds: Vec<Cmd>,
}
During election, a candidate chooses terms.len() as its term. After it becomes leader, both the missing-command gap slots and later log entries use this leader term. Replication and commitment still follow the basic Raft rules.
That is the core of this experimental implementation: keep Raft’s logical time model, but change where that logical time comes from in persistent state.
Repository: raf (v0.1.1).
Reference:
本文链接: https://blog.openacid.com/algo/raf-without-term/

留下评论